
哪种显卡能提供最快的人工智能?
")
人工智能和深度学习最近不断成为头条新闻,无论是ChatGPT产生的不良建议,自动驾驶汽车,艺术家被指控使用人工智能,人工智能的医疗建议,等等。这些工具大多依靠复杂的服务器和大量的硬件进行训练,但通过推理使用训练过的网络可以在你的PC上,使用其显卡来完成。但是,消费类GPU做人工智能推理的速度如何?
我们在最新的Nvidia、AMD、甚至英特尔的GPU上对Stable Diffusion进行了基准测试,看看它们的表现如何。如果你碰巧尝试过在自己的电脑上启动和运行Stable Diffusion,你可能会对这一过程的复杂性--或简单性--有一些印象。- 这可能是多么复杂或简单。简而言之,Nvidia的GPU占主导地位,大多数软件都使用CUDA和其他Nvidia工具集设计。但这并不意味着你不能在其他GPU上运行Stable Diffusion。
我们最终使用了三个不同的Stable Diffusion项目进行测试,主要是因为没有一个软件包可以在每个GPU上运行。对于Nvidia,我们选择了Automatic 1111的webui版本;它表现最好,有更多的选项,而且很容易运行。AMD GPU使用Nod.ai的Shark版本进行测试--我们检查了Nvidia GPU的性能(在Vulkan和CUDA模式下),发现它...缺乏。由于缺乏支持,让英特尔的Arc GPU运行起来比较困难,但Stable Diffusion OpenVINO给了我们一些非常基本的功能。
免责声明是有必要的。我们没有对这些工具进行编码,但我们确实在寻找那些容易运行的工具(在Windows下),而且似乎也得到了合理的优化。我们比较有信心的是,Nvidia 30系列测试在提取接近最佳性能方面做得很好--特别是当xformers被启用时,它提供了额外的约20%的性能提升(尽管精度降低,可能影响质量)。同时,RTX 40系列的结果最初较低,但George SV8ARJ提供了这个修复方法,其中更换PyTorch CUDA DLLs对性能有一个健康的提升。
AMD的结果也有点喜忧参半。RDNA 3 GPU表现非常好,而RDNA 2 GPU似乎相当平庸。Nod.ai让我们知道他们仍在为RDNA 2的 "调整 "模型工作,一旦它们可用,性能应该会有相当大的提升(可能是两倍)。最后,在英特尔GPU上,尽管最终的性能似乎与AMD的选项一致,但在实践中,渲染的时间大大延长--在实际生成任务开始之前需要5-10秒,而且可能有很多额外的后台东西正在发生,使其变慢。
由于软件项目的选择,我们也在使用不同的Stable Diffusion模型。Nod.ai的Shark版本使用SD2.1,而Automatic 1111和OpenVINO使用SD1.4(尽管在Automatic 1111上可以启用SD2.1)。同样,如果你对Stable Diffusion有一些内部知识,并且想推荐不同的开源项目,这些项目可能比我们使用的项目运行得更好,请在评论中告诉我们(或者直接给Jarred发邮件)。
")

正面提示:
postapocalyptic steampunk city, exploration, cinematic, realistic, hyper detailed, photorealistic maximum detail, volumetric light, (((focus))), wide-angle, (((brightly lit))), (((vegetation))), lightning, vines, destruction, devastation, wartorn, ruins
负面的提示:
(((blurry))), ((foggy)), (((dark))), ((monochrome)), sun, (((depth of field)))
步数:
100
分类器自由指导:
15.0
采样算法:
某种欧拉变体(自动1111的祖先,AMD的鲨鱼欧拉离散)。
采样算法似乎不会对性能产生重大影响,尽管它可能会影响输出。自动1111提供了最多的选择,而英特尔的OpenVINO构建则没有给你任何选择。
以下是我们对AMD RX 7000/6000系列、Nvidia RTX 40/30系列和Intel Arc1 A系列GPU的测试结果。请注意,每个Nvidia GPU都有两个结果,一个是使用默认的计算模型(速度较慢,呈黑色),另一个是使用来自Facebook的更快的 "xformers "库(速度较快,呈绿色)。
")
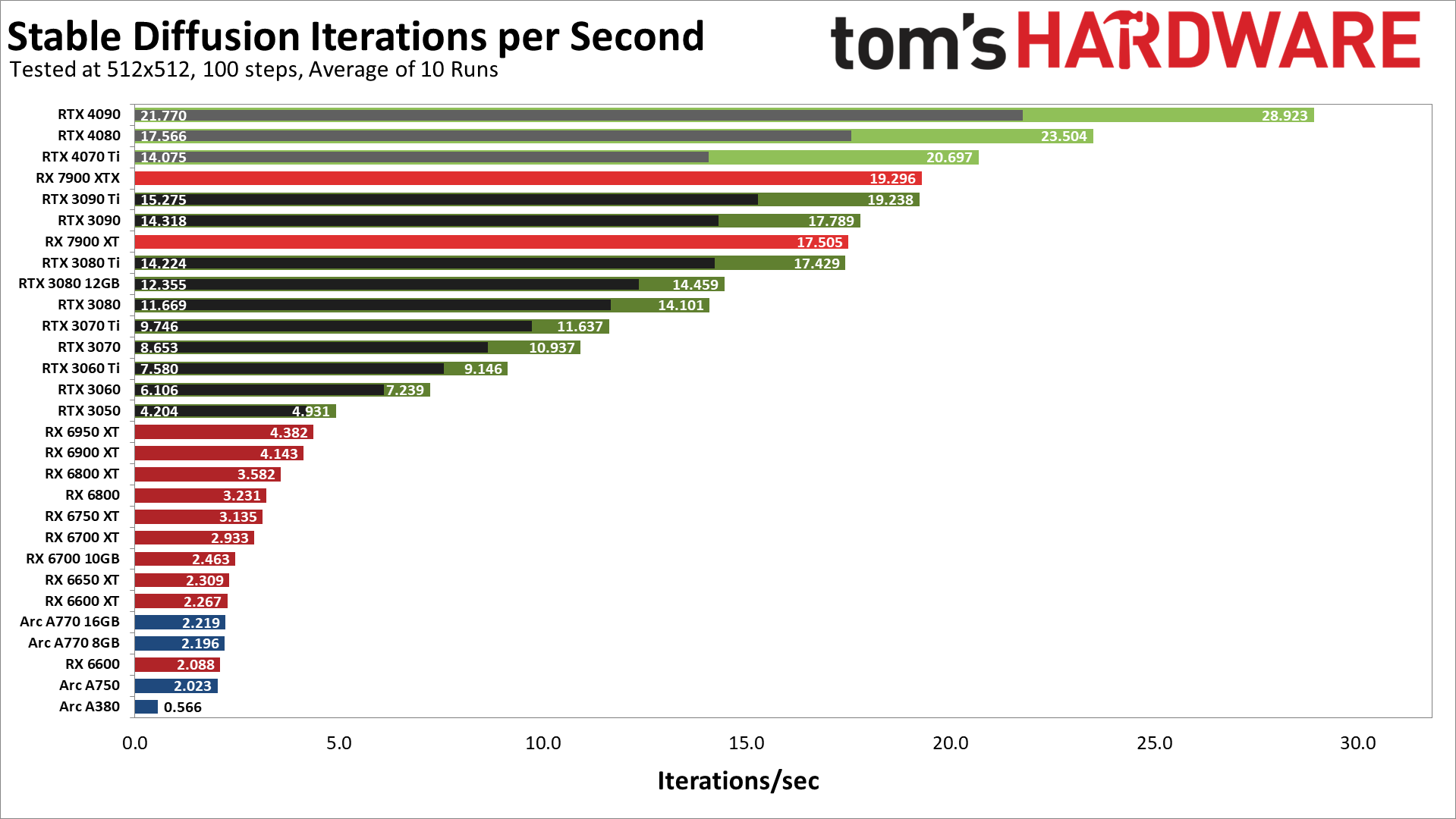
正如预期的那样,与AMD或英特尔的任何产品相比,Nvidia的GPU提供了卓越的性能--有时是以巨大的优势。随着Torch的DLL修复到位,RTX 4090的性能比带有xformers的RTX 3090 Ti高出50%,而没有xformers的性能则高出43%。生成每张图片只需要三秒多,甚至RTX 4070 Ti也能勉强超过3090 Ti(但如果你禁用xformers就不行)。
从Nvidia GPU的顶级卡中,事情以相当一致的方式下降,从3090下降到3050。同时,AMD的RX 7900 XTX与RTX 3090 Ti并驾齐驱(经过额外的重新测试),而RX 7900 XT与RTX 3080 Ti并驾齐驱。7900卡看起来相当不错,而每张RTX 30系列卡最终都能击败AMD的RX 6000系列部件(目前)。最后,英特尔Arc GPU几乎排在最后,只有A770设法超过了RX 6600。让我们再来谈一谈这些差异。
**
**
适当的优化可以使RX 6000系列卡的性能提高一倍。Nod.ai说,它应该在未来几天内为RDNA 2调整模型,届时整体性能应该开始与理论性能有更好的关联。说到Nod.ai,我们也使用该项目对一些Nvidia GPU做了一些测试,在Vulkan模型下,Nvidia显卡的速度大大低于Automatic 1111的构建(4090的15.52 it/s,4080的13.31,3090 Ti的11.41,3090的10.76 - 我们无法测试其他显卡,因为它们需要先被启用)。
基于7900卡使用调谐模型的性能,我们也很好奇Nvidia卡以及它们能够从其Tensor核心中获得多少好处。在纸面上,4090的性能是RX 7900 XTX的五倍以上--即使我们不考虑稀缺性,也是2.7倍。在实践中,现在的4090在我们使用的版本中只比XTX快50%左右(如果我们省略精度较低的xformers结果,则下降到只有13%)。这同样的逻辑也适用于英特尔的Arc卡。
英特尔的Arc GPU目前提供了非常令人失望的结果,特别是由于它们支持FP16 XMX(矩阵)操作,应该提供高达4倍于常规FP32计算的吞吐量。我们怀疑目前我们使用的Stable Diffusion OpenVINO项目也有很大的改进空间。顺便提一下,如果你想尝试在Arc GPU上运行SD,请注意你必须编辑'stable_diffusion_engine.py'文件,将 "CPU "改为 "GPU"--否则它就不会使用显卡进行计算,而且需要花费大量时间。
那么总的来说,使用指定的版本,Nvidia的RTX 40系列卡是最快的选择,其次是7900卡,然后是RTX 30系列的GPU。RX 6000系列表现不佳,而Arc GPU看起来普遍较差。随着软件的更新,情况可能会发生根本性的变化,考虑到人工智能的普及,我们预计看到更好的调校只是时间问题(或者找到已经调校好的正确项目,提供更好的性能)。
")
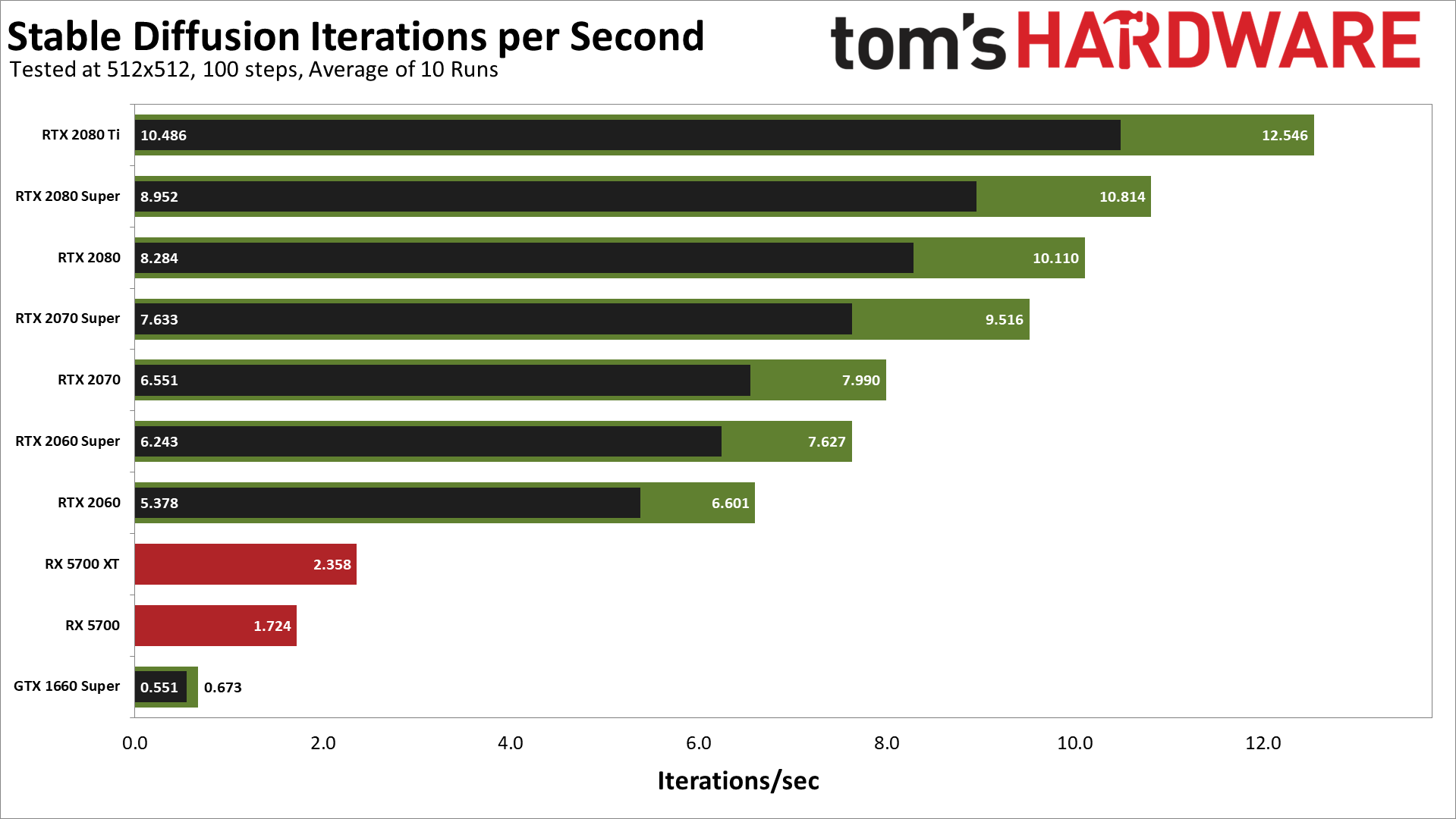
我们还对传统的GPU进行了一些测试,特别是Nvidia的图灵架构(RTX 20-和GTX 16-系列)和AMD的RX 5000-系列。RX 5600 XT失败了,所以我们在RX 5700的测试中离开了,而GTX 1660超级版的速度很慢,我们觉得没有必要对低级别部件做进一步的测试。但这里的结果是相当有趣的。
首先,RTX 2080 Ti的表现最终超过了RTX 3070 Ti。这通常不会发生,在游戏中,即使是虚构的3070也往往会击败前冠军。更重要的是,这些数字表明,Nvidia在安培架构中的 "稀疏性 "优化根本没有被使用--或者也许它们根本不适用。
我们一会儿会讨论一些其他的理论计算性能数字,但再次考虑RTX 2080 Ti和RTX 3070 Ti作为一个例子。2080 Ti的张量核心不支持稀疏性,有高达108 TFLOPS的FP16计算。RTX 3070 Ti支持稀疏性,有174 TFLOPS的FP16,或87 TFLOPS的FP16,不支持稀疏性。2080 Ti击败3070 Ti的事实清楚地表明,稀疏性并不是一个因素。同样的逻辑适用于其他比较,如2060和3050,或2070超级和3060 Ti。**
**
至于AMD的RDNA卡,RX 5700 XT和5700,在性能上有很大差距。5700 XT仅比6650 XT领先,但5700低于6600。从纸面上看,XT卡的速度应该高达22%。然而,在我们的测试中,它的速度是37%。无论哪种方式,在我们最初的Stable Diffusion基准测试中,老的Navi 10 GPU都没有特别的表现。
最后,GTX 1660超级版在纸面上的理论性能应该是RTX 2060的1/5左右,使用后者的Tensor核心。如果我们使用FP16的着色器性能(图灵在FP16着色器代码上有两倍的吞吐量),差距缩小到只有22%的赤字。但是在我们的测试中,GTX 1660超级版的速度只有RTX 2060的1/10左右。
同样,目前还不清楚这些项目到底有多优化。也不清楚这些项目是否完全利用了诸如Nvidia的Tensor核心或英特尔的XMX核心。因此,我们认为看一下各种GPU的最大理论性能(TFLOPS)会很有趣。下图显示了每个GPU的FP16理论性能(只看较新的显卡),在适用的地方使用张量/矩阵核心。Nvidia的结果还包括稀缺性--基本上是在矩阵中最多一半的单元中跳过乘以0的能力,据说这在深度学习工作负载中是一个相当频繁的现象。
")
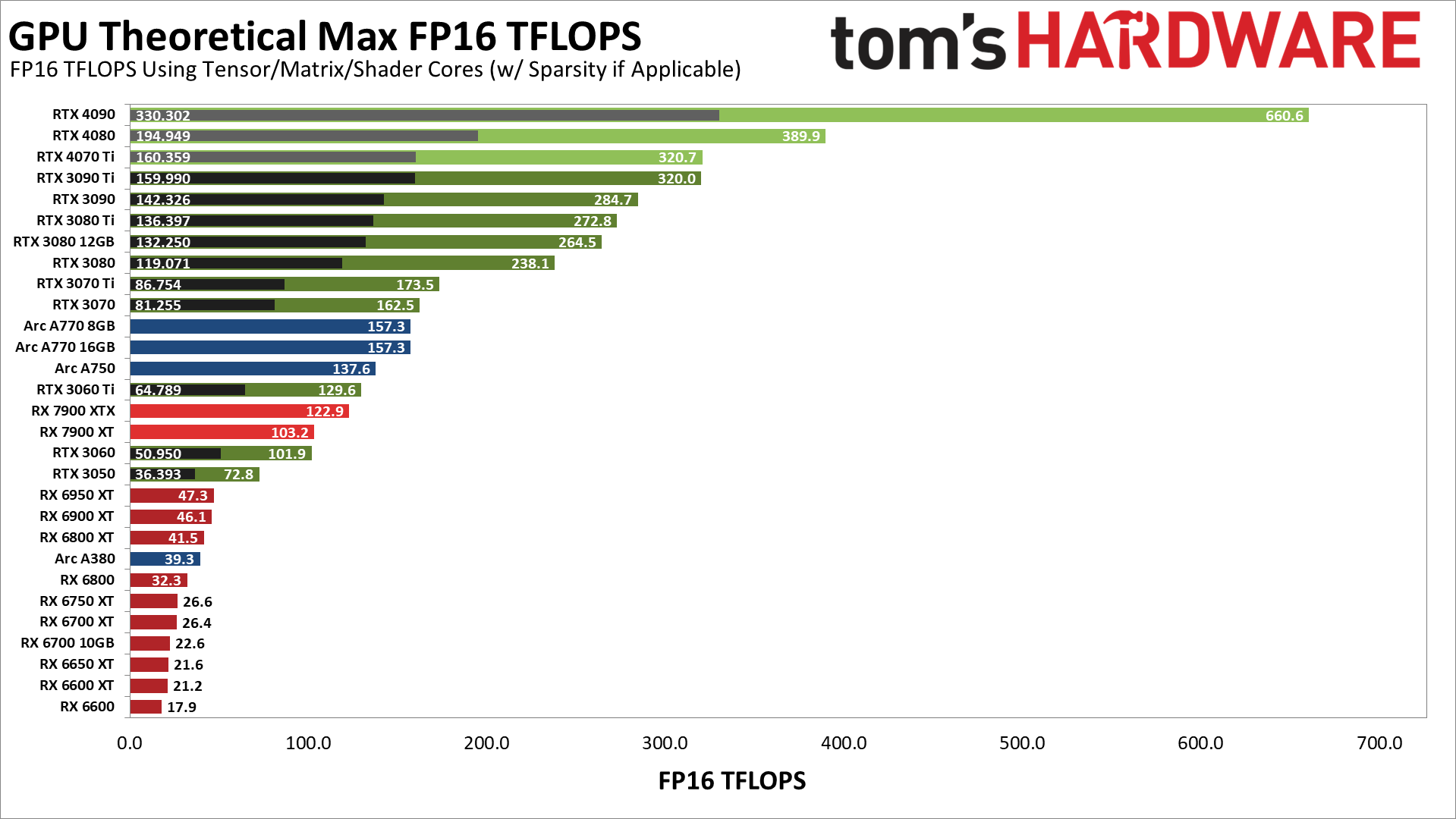
Nvidia的那些Tensor核心显然是有冲击力的(灰色/黑色条是没有稀疏性的),显然我们的Stable Diffusion测试与这些数字不完全吻合--甚至不接近。例如,在纸面上,RTX 4090(使用FP16)比RTX 3090 Ti快106%,而在我们的测试中,它在没有xformers的情况下快43%,而在有xformers的情况下快50%。还要注意的是,我们假设我们使用的Stable Diffusion项目(自动1111)没有利用Ada Lovelace GPU上的新FP8指令,这有可能使RTX 40系列的性能再次翻倍。
同时,看看Arc GPU。他们的矩阵核心应该提供类似于RTX 3060 Ti和RX 7900 XTX的性能,给或不给,A380下降到RX 6800左右。在实践中,Arc GPU远远没有达到这些分数。最快的A770 GPU介于RX 6600和RX 6600 XT之间,A750仅次于RX 6600,而A380的速度大约是A750的四分之一。因此,它们都是预期性能的四分之一,如果不使用XMX核心,这将是合理的。
不过,Arc上的内部比率看起来确实差不多。A380的理论计算性能大约是A750的四分之一,这也是它现在在Stable Diffusion性能方面的位置。最有可能的是,Arc GPU正在使用着色器进行计算,在全精度FP32模式下,错过了一些额外的优化。
另一件需要注意的事情是,与RX 6000系列相比,AMD的RX 7900 XTX/XT的理论计算能力提高了很多。我们得看看经过调整的6000系列型号是否能缩小差距,因为Nod.ai说它期望在RDNA 2上的性能有大约2倍的提高。 内存带宽并不是一个关键因素,至少对于我们使用的512x512目标分辨率而言--3080的10GB和12GB型号落在一起相对较近。
")
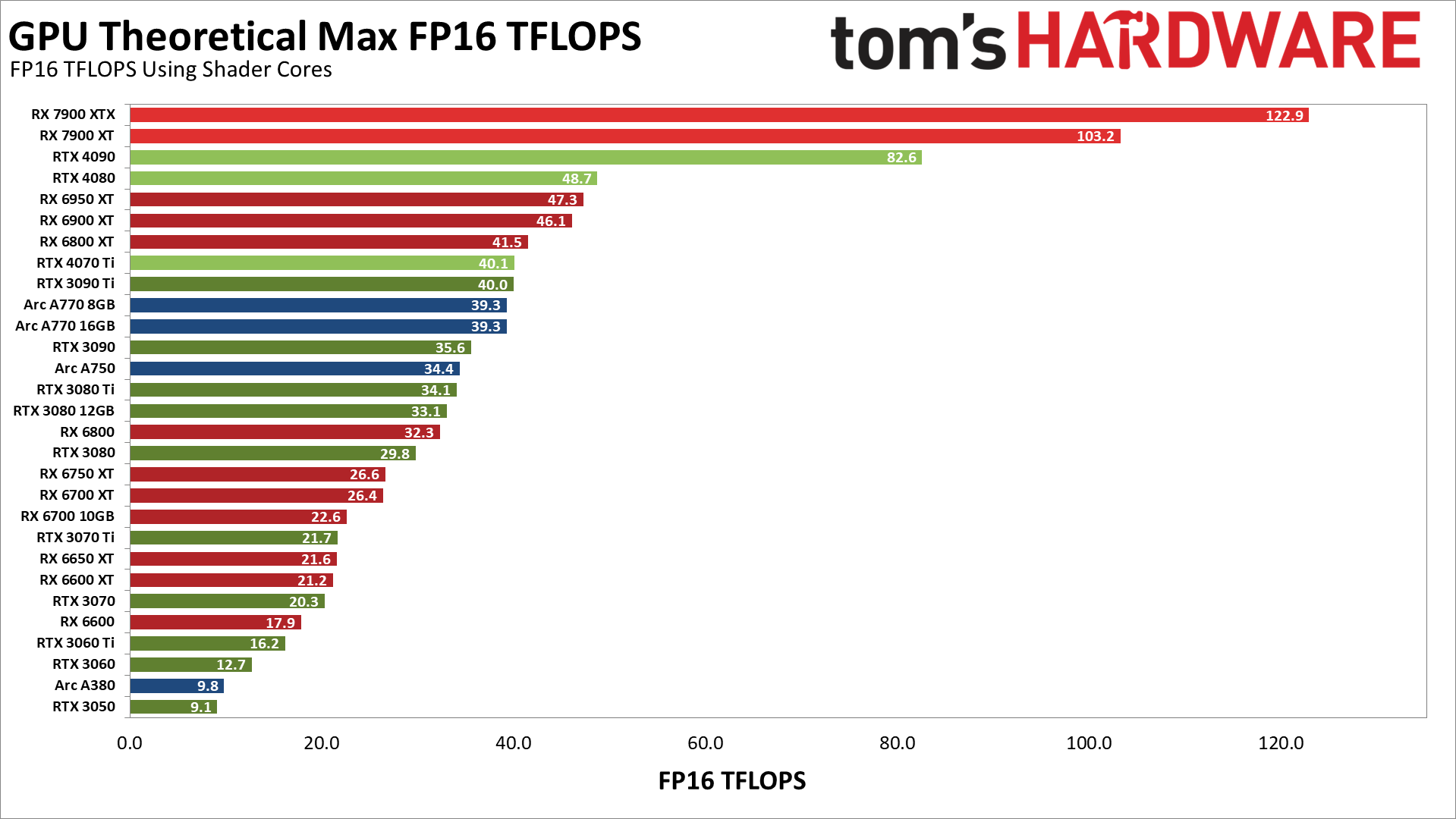
下面是对FP16理论性能的不同看法,这次只关注各种GPU通过着色器计算能做什么。Nvidia的Ampere和Ada架构以与FP32相同的速度运行FP16,因为假设FP16可以被编码为使用Tensor核心。相比之下,AMD和英特尔的GPU在FP16着色器计算上的性能是FP32的两倍。
很明显,这第二张FP16计算的图表与我们的实际性能相比,并没有更好的张量和矩阵核心的图表,但也许在设置矩阵计算时有额外的复杂性,所以完整的性能需要...额外的东西。这给我们带来了最后一个图表。
")
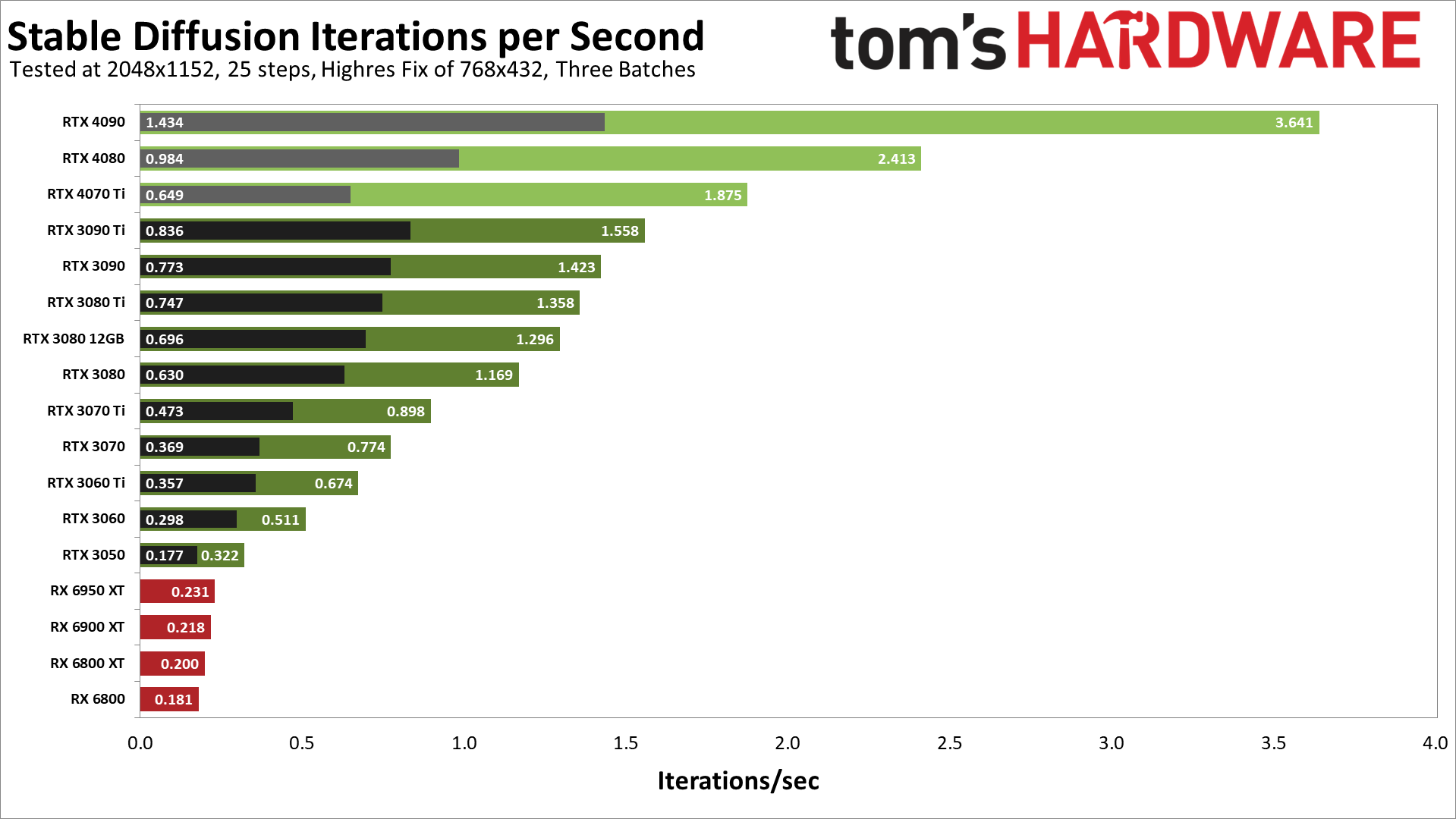
这张最后的图表显示了我们更高的分辨率测试结果。我们没有测试新的AMD GPU,因为我们必须在AMD RX 6000系列显卡上使用Linux,显然RX 7000系列需要一个更新的Linux内核,而我们无法让它工作。但请看RTX 40系列的结果,替换了Torch DLLs。
RTX 4090现在比没有xformers的3090 Ti快72%,而用xformers则快了高达134%。4080也比3090 Ti快55%/18%,有/没有xformers。有趣的是,4070 Ti在没有xformers的情况下比3090 Ti慢22%,但在有xformers的情况下快20%。
看起来更复杂的2048x1152目标分辨率开始更好地利用潜在的计算资源,也许更长的运行时间意味着Tensor核心可以充分地发挥它们的力量。
归根结底,这充其量只是Stable Diffusion性能的一个时间快照。我们看到频繁的项目更新,对不同训练库的支持,以及更多。我们将在来年更多地重温这个话题,希望能有更好的优化代码用于所有不同的GPU。
如若转载,请注明出处:https://www.ozabc.com/tansuo/535104.html